
对于 AI 行业从业者来说,刚刚可能是一夜未眠。
北京时间 5月 15 日凌晨,美国人工智能公司 OpenAI 的春季功能更新会正式召开。OpenAI 首席技术官 Mira Murati发布了公司的最新模型GPT-4o。据介绍,GPT-4o速度是GPT-4(特别是GPT-4 Turbo)的两倍,价格只有一半,且升级了模型在文本、视觉和音频方面的功能。
当然,更重要的是,基于GPT-4o,OpenAI还对ChatGPT做了更新,增加了更强的语音和视觉功能,这让ChatGPT对现实的感知能力大大增强。
在Google I/O发布会前夕,OpenAI用GPT-4o的发布再次向外界证明了,自己是大模型领域毋庸置疑的领先者。
/ 01 /
GPT-4o,更快、更强
发布会一开始,OpenAI 首席技术官 Mira Murati就宣布了 GPT-4 的一次大升级,推出了GPT-4o(“o”代表“omni”)。作为最新发布的模型,GPT-4o拥有更快的速度,并且升级了模型在文本、视觉和音频方面的功能。
具体来说,GPT-4o大致有以下四个升级:更强的多模态能力、多语言能力的提升、更强的视觉和音频理解、更快的速度和更低的价格。
第一,GPT-4o能够接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合输出,是真正意义上的多模态模型。
对于这个能力,OpenAI做了17个案例展示,其中包括照片转漫画、3D物体合成、海报创作、角色设计等样本。在角色设计案例里,用户先是向模型输入角色的相关指令,并得到了一个机器人角色形象。
随后用户可以根据这一形象,自行设计角色的相关动作,包括玩飞盘、编程、骑自行车等等。 第二,更强的多语言能力,GPT-4o 50 种不同语言中的性能得到了提高,包括改进了分词器以更好地压缩其中的许多语言。GPT-4o 比 Whisper-v3 显着提高了所有语言的语音识别性能,特别是对于资源匮乏的语言。
第二,更强的多语言能力,GPT-4o 50 种不同语言中的性能得到了提高,包括改进了分词器以更好地压缩其中的许多语言。GPT-4o 比 Whisper-v3 显着提高了所有语言的语音识别性能,特别是对于资源匮乏的语言。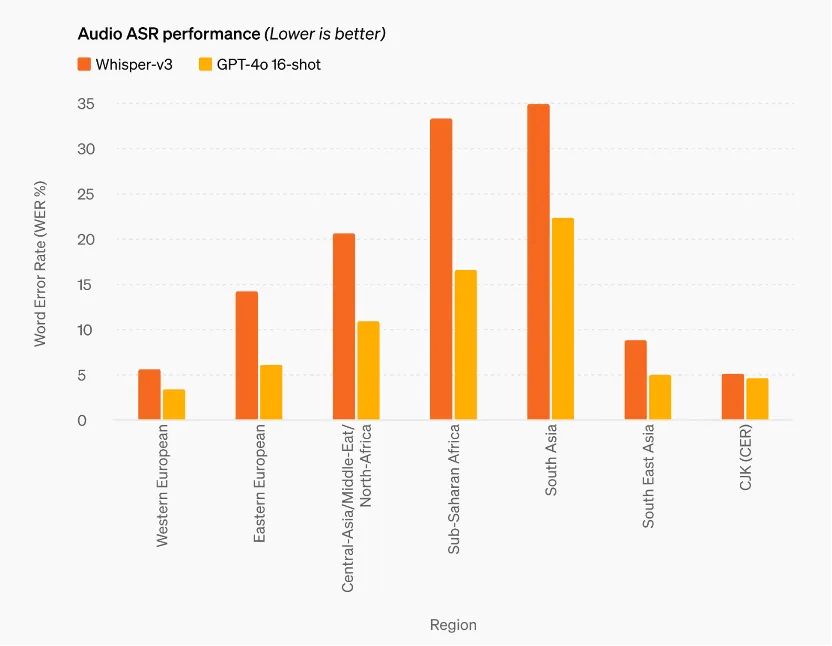 第三,与现有模型相比,GPT-4o 在视觉和音频理解方面尤其出色。根据传统基准测试,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上实现了更高水平的突破。
第三,与现有模型相比,GPT-4o 在视觉和音频理解方面尤其出色。根据传统基准测试,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上实现了更高水平的突破。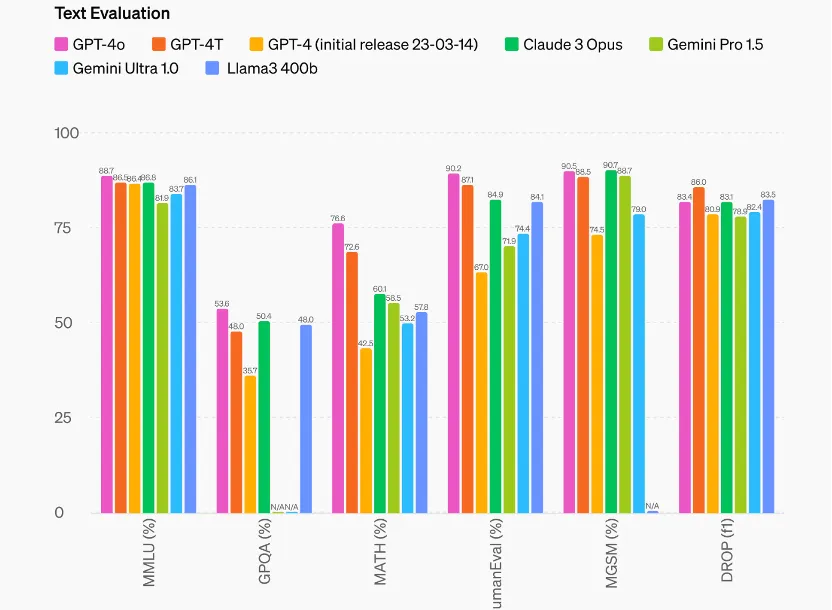 在音频性能上,GPT-4o 在语音翻译方面树立了新的最先进水平,并且在MLS基准测试中优于 Whisper-v3。
在音频性能上,GPT-4o 在语音翻译方面树立了新的最先进水平,并且在MLS基准测试中优于 Whisper-v3。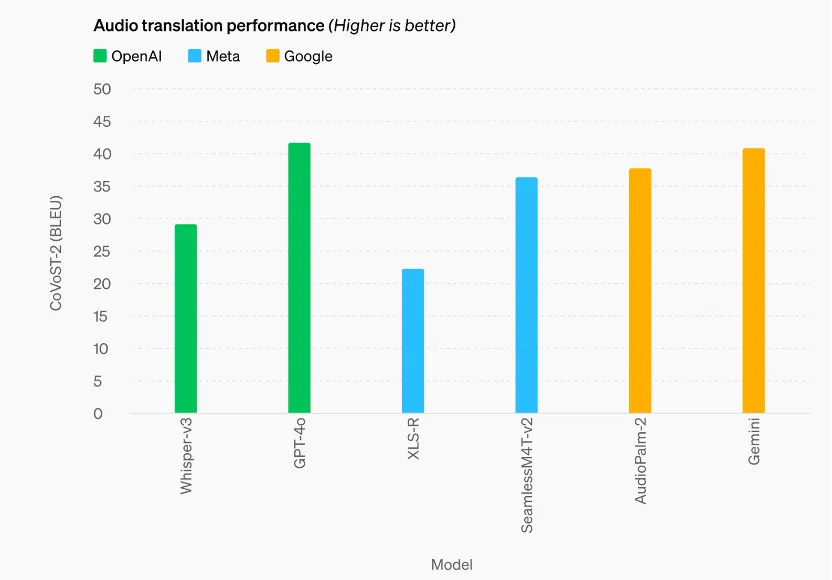
视觉理解方面,GPT-4o在M3Exam基准和视觉感知基准上都有不错的表现。其中,M3Exam基准是多语言和视觉评估,由来自其他国家标准化测试的多项选择题组成,有时包括图形和图表。在所有语言的基准测试中,GPT-4o都比 GPT-4更强。
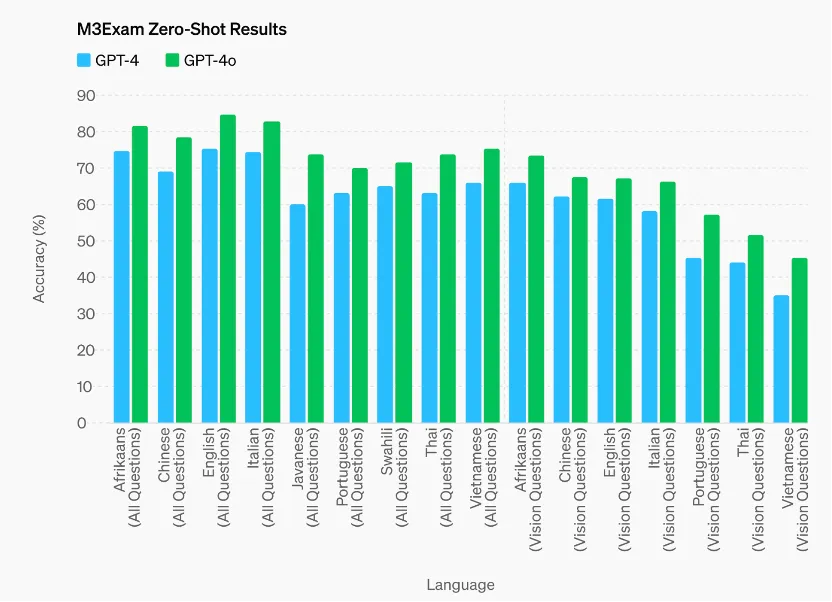 视觉理解评估 GPT-4o 在视觉感知基准上实现了最先进的性能。
视觉理解评估 GPT-4o 在视觉感知基准上实现了最先进的性能。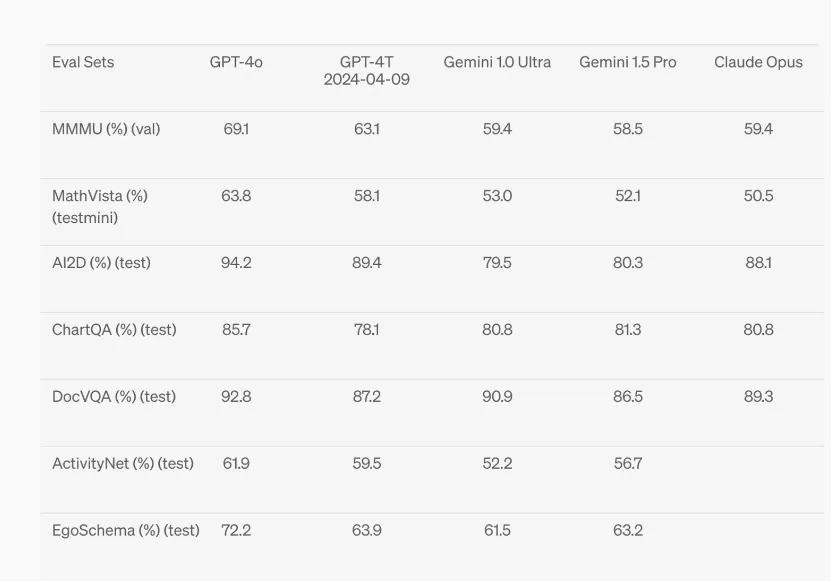
在性能提升的同时,GPT-4o不仅速度更快了,价格也更便宜了。在OpenAI的API中,GPT-4o的速度是GPT-4(特别是GPT-4 Turbo)的两倍,价格只有一半,并且具有更高的速率限制。
/ 02 /
新版ChatGPT来了
随着GPT-4o的发布,OpenAI也对ChatGPT做了更新,增加了语音模式。与传统的语音模式不同,ChatGPT的语音模式有三大特点:
一是交互过程中,可以随时打断;二是模型是实时响应,几乎没有延迟;三是模型更注重交互的情绪,不仅能够听懂你的情绪,也能够生成不同风格和情感的声音。
过去,人跟AI进行语音对话,基本上都经历3步:1)你说的话,AI进行语音识别,即音频转文本;2)大模型拿到这段文本,进行回复,产出文本;3)讲大模型的产出文本进行语音合成,变成音频。
由于上述转化过于繁琐,因此在转化过程中会造成大量信息的损耗,既无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。而借助GPT-4o,OpenAI跨文本、视觉和音频端到端地训练了一个新模型,这意味着所有输入和输出都由同一神经网络处理,效率得到了大幅提升。当语音和视觉功能结合起来,能够明显看到ChatGPT对现实环境的感知能力大大加强,甚至带来了更多的应用场景。比如,通过视频画面,ChatGPT能够分析出你当下所处的环境以及可能在做的一些事情。
除此之外,ChatGPT甚至还能和你一起逗狗。
这一切的一切,都让ChatGPT越来越像一个人,而非AI。按照 Sam Altman 的说法,新的语音模式将在未来几周内面向 Plus 用户上线。
/ 03 /
GPT-4o,尚未完成训练的GPT-5?
在OpenAI发布会后,众人也纷纷给出了自己的积极评价。
宾夕法尼亚大学沃顿商学院教授伊森·莫里克表示,GPT-4o 非常令人印象深刻,非常快,明显比 GPT-4 更聪明(尽管没有 GPT-5 更聪明),视觉更好。尽管潜在能力并不是巨大的飞跃,但实际上向前迈出了一大步。

英伟达高级人工智能科学家范吉姆(Jim Fan)在X上表示,OpenAI 已经找到了一种将音频直接映射到音频的方法,作为一流的模态,并将视频实时传输到变压器。这些需要对标记化和架构进行一些新的研究,但总的来说,这是一个数据和系统优化问题(就像大多数事情一样)。
在他看来,此次发布的GPT-4o 可能更加接近 GPT-5,甚至可能是尚未完成训练的GPT-5。尤其在Google I/O 大会之前,OpenAI 宁愿击碎市场对GPT-4.5的心理预测,也不愿市场因错过对 GPT-5 的极高期望而失望。这也为OpenAI争取到了更多的时间。
在OpenAI发布会结束后,Sam Altman也发表了一则博客。以下是博客原文:
在我们今天的公告中,我想强调两件事。
首先,我们使命的一个关键部分是将非常强大的人工智能工具免费(或以优惠的价格)提供给人们。我非常自豪我们在 ChatGPT 中免费提供了世界上最好的模型,没有广告或类似的东西。
当我们创办 OpenAI 时,我们最初的想法是我们要创造人工智能并利用它为世界创造各种利益。相反,现在看起来我们将创造人工智能,然后其他人将使用它来创造各种令人惊奇的事物,让我们所有人都受益。
我们是一家企业,会发现很多东西需要收费,这将有助于我们向(希望如此)数十亿人提供免费、出色的人工智能服务。
其次,新的语音(和视频)模式是我用过的最好的计算机界面。感觉就像电影里的人工智能一样;我仍然有点惊讶它是真的。事实证明,达到人类水平的响应时间和表达能力是一个巨大的变化。
最初的 ChatGPT 暗示了语言界面的可能性;这个新事物感觉本质上是不同的。它快速、智能、有趣、自然且有帮助。
对我来说,与电脑交谈从来都不是很自然的事情。现在确实如此。当我们添加(可选)个性化、访问您的信息、代表您采取行动的能力等等时,我确实可以看到一个令人兴奋的未来,我们能够使用计算机做比以往更多的事情。
除了语音功能外,ChatGPT还新增了视觉功能,并做了现场演示。与此前模型上传图片不同,演示人员直接用手机打开了摄像头,并进行了现场答题。
免责声明:本文来自乌鸦智能说客户端,不代表超天才网的观点和立场。文章及图片来源网络,版权归作者所有,如有投诉请联系删除。




















