
智能手机语音识别就是通过手机硬件与软件系统来识别和理解人类语音信号并进行相应处理的技术。简单地说,智能手机语音识别就是让智能手机听懂人类的语音,并且与人进行相应的交互与沟通,甚至帮助人作出一定的决策。未来,语音识别技术不仅限于智能手机,而且会在医疗、网络教育、家庭服务、工业控制、汽车、家电等智能控制领域大放异彩。
语音识别涉及语言学、声学、信号处理、通信技术、生理学、心理学、逻辑数学等诸多交叉领域,该项技术在未来有着非常广阔的市场应用前景,彻底改观人类的精神风貌。
语音识别的关键技术
本质上讲,智能手机语音识别属于模式识别的分支,包括语音单元的选择、特征提取、模式匹配与模式库等三个基本环节和过程:
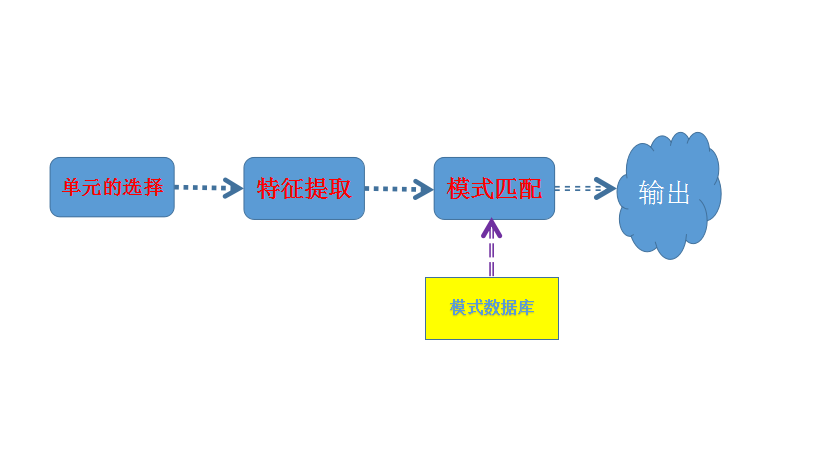
(一)语音识别单元的选择
语音识别单元有单词、音节和音素三个类型。单词广泛应用于中小词汇语音识别,但不适合大词汇系统,原因在于模型库太庞大,训练模型任务繁重,模型匹配算法复杂。音节对于中、大词汇量,比如汉语语音识别来说,以音节为识别单元是比较容易实现。音素单元多用于英语语音识别系统中,但目前中、大词汇量汉语语音识别系统也在越来越多地采用。
(二)特征提取
特征提取就是提取出对语音识别有用的信息,它对语音信号进行分析处理,去除无关紧要的冗余信息,获得影响语音的重要信息。对于非特定人语音识别来讲,希望特征参数尽可能多的反映语义信息,尽量减少说话人的个人信息。例如,常用的提取算法模型有:
线性预测(LP)分析技术是目前应用广泛的特征参数提取技术,许多成功的应用系统都采用基于LP技术提取的倒谱参数。但线性预测模型是纯数学模型,没有考虑人类听觉系统对语音的处理特点。
‚Mel参数和基于感知线性预测(PLP)分析提取的感知线性预测倒谱,在一定程度上模拟了人耳对语音的处理特点,应用了人耳听觉感知方面的一些研究成果。采用这种技术,语音识别系统的性能有一定提高。
ƒ小波分析技术应用于特征提取,但目前其性能有待进一步研究。

(三)模式匹配与模式库
要进行模式匹配就必须建立相应的模式库,以确立相应的对比匹配。即从大量已知模式中获取表征该模式本质特征的模型参数,而模式匹配则是根据一定准则,使未知模式与模型库中的某一个模型获得最佳匹配。
语音模式匹配技术主要有动态时间归正技术(DTW)、隐马尔可夫模型(HMM)和人工神经元网络(ANN)。
DTW是较早的一种模式匹配和模型训练技术,它应用动态规划方法成功解决了语音信号特征参数序列比较时长不等的难题,在孤立词语音识别中获得了良好性能。
‚HMM模型是语音信号时变特征的有参表示法。它由相互关联的两个随机过程共同描述信号的统计特性,其中一个是隐蔽的具有有限状态的Markor链,另一个是与Markor链的每一状态相关联的观察矢量的随机过程。隐蔽Markor链的特征要靠可观测到的信号特征揭示。这样,语音等时变信号某一段的特征就由对应状态观察符号的随机过程描述,而信号随时间的变化由隐蔽Markor链的转移概率描述。模型参数包括HMM拓扑结构、状态转移概率及描述观察符号统计特性的一组随机函数。按照随机函数的特点,HMM模型可分为离散隐马尔可夫模型(采用离散概率密度函数,简称DHMM)和连续隐马尔可夫模型(采用连续概率密度函数,简称CHMM)以及半连续隐马尔可夫模型(SCHMM,集DHMM和CHMM特点)。一般来讲,在训练数据足够的CHMM优于DHMM和SCHMM。
ƒ人工神经元网络在语音识别中的应用是现在研究的又一热点。ANN本质上是一个自适应非线性动力学系统,模拟了人类神经元活动的原理,具有自学、联想、对比、推理和概括能力。
应该指出的是,由于不同民族、不同方言以及各个人不同的语言习惯,会造成语音识别的个性差异,所以语音识别系统必须建立尽可能详尽的参数库,去适应每个个体的发音习惯、用词习惯,甚至情感习惯。如果这个数据库足够完备,其准确度会相应提高。这个个人数据库需要让机器长时间的学习积累,以丰富其模式储备。在智能手机上应用时,还可以在更换手机时让新手机继承以前手机的数据库。
语音识别所面临的技术障碍
(一)目前智能语音识别率不高以及语义曲解是阻碍用户使用智能语音的一个现实原因。要解决这一问题,必须在人工智能和模式数据库上取得革命性突破。而如果这个模式数据库能匹敌人类大脑的话,这个数据库将极其庞大,这个庞大的数据库让当下的手机软硬件难以支撑。
(二)语音识别对环境依赖性强,经过某一环境的训练学习后,在别的环境下性能有一个急剧的下降。另外,噪音环境下语音识别困难,此时对语音不同音频的抽取会更加困难。
(三)人类对听觉的感知是一个极其复杂的过程,虽然机器对知识积累和模仿人脑神经系统方面有了长足的进步,但完全揭示人类对语音感知机理目前还仅处于初级阶段。因此,机器取代人类感知语音还有一个相对漫长的探索过程,目前的各种算法相较于人类的语音感知还过于简单。
正是基于以上难题,语音识别系统目前还仅限于一些简单的应用,其应用场景范围也非常有限。如果商家盲目推广,必将降低自身产品的用户体验,带来负面市场效应。
语音识别前景展望
毋庸置疑,全球涉及人工智能应用的公司一致看好语音识别的未来前景,当计算机问世以来,科技界一直致力于这一技术的研发,脚步一刻也没停。随着智能手机铺天盖地的进入人们的生活,科技界明显加快了这项技术的研发节奏,期待掀起新一轮颠覆性革命。美国IT界的领先公司个个跃马扬鞭,不甘落后。苹果、谷歌、微软、Facebook等纷纷推出各自的概念产品。
(一)苹果的Siri系列
2011年苹果将语音识别技术融入到iPhone 4S中并发布了Siri语音助理。该技术是通过收购Siri Inc.获取的,但iPhone4s发布后,Siri的用户体验反馈远远低于之前预期,甚至带来负面效果。苹果2013年又收购了Novauris Technologies。Novauris的系统可识别2.45亿个短语,并具有理解上下文的简单功能,Siri向前迈了一大步,但离完美还相去甚远。2016年苹果又收购了英国语音技术公司VocalIQ和美国 AI 技术公司 Emotient,接收其脸部表情分析与情绪辨别技术。由此可见苹果在语音识别领域的勃勃雄心。
(二)谷歌的Google Now系列
2011年谷歌出手收购语音通信公司SayNow和语音合成公司Phonetic Arts。2012年推出的产品可实现点对点对话并可以把录制的语音对话转化成语音库,生成逼真的人声对话。2013年谷歌又以超过3000万美元收购了新闻阅读应用开发商Wavii,Wavii可扫描互联网定位新闻,并输出一句摘要及链接。之后,谷歌又收购了多项语音识别相关的专利,谷歌期待打造语音识别引擎。另外,谷歌在语音导航等领域也有布局。
(三)微软的Cortana、小冰和Skype Translator系列
Cortana可以记录用户的行为和使用习惯,利用云计算、搜索引擎和“非结构化数据”分析,读取和学习包括手机中的图片、视频、电子邮件等数据理解用户的语义和语境,从而实现人机交互。小冰具有智能对话和群提醒、百科、天气、星座、笑话、交通指南、餐饮点评等功能。Skype Translator,可以为英语、西班牙语、汉语、意大利语用户进行实时翻译。
(四)Facebook的Jibbigo系列
Facebook的产品Jibbigo允许用户在25种语言中选择一种语言进行语音片段录制或文本输入,然后大声朗读出来,成为出国旅游的用语手册。

综上,在移动互联网时代,由于终端小型化,语音识别在人机交互中将适逢绝佳的市场机遇。尽管语音识别还面临诸多障碍,但随着云计算、大数据以及半导体技术的突飞猛进,语音识别的技术障碍必将被逐个逾越,语音识别必将迎来美好的春天。
免责声明:本文来自超天才网客户端,不代表超天才网的观点和立场。文章及图片来源网络,版权归作者所有,如有投诉请联系删除。





















